I think it’s high time I authored a completely opinion-based article full of observations and my own prejudices that might result in a littany of ad hominem attacks and insults. Or at least, I hope it does. This little bit of prose will outline my view of the world of programmable logic as I see it today. Again, it is as I see it. You might see it differently. But you would be wrong.
First let’s look at the players. The two headed Cerberus of the programmable logic world is Altera and Xilinx. They battle it out for the bulk of the end-user market share. After that, there are a series of niche players (Lattice Semiconductor, Microsemi (who recently purchased Actel) and Quicklogic), lesser lights (Atmel and Cypress) and wishful upstarts (Tabula, Achronix and SiliconBlue).
Atmel and Cypress are broadline suppliers of specialty semiconductors. They each sell a small portfolio of basic programmable logic devices (Atmel CPLDs, Atmel FPGAs and Cypress CPLDs). As best I can tell, they do this for two reasons. First, they entered the marketplace and have been in it for about 15 years and at this point have just enough key customers using the devices such that the cost of exiting the market would be greater than the cost of keeping these big customers happy. The technology is not, by any stretch of the imagination, state of the art so the relative cost of supporting and manufacturing these parts is small. Second, as a broadline supplier of a wide variety of specialty semiconductors, it’s nice for their sales team to have a PLD to toss into a customer’s solution to stitch together all that other stuff they bought from them. All told, you’re not going to see any profound innovations from these folks in the programmable logic space. ‘Nuff said about these players, then.
At the top of the programmable logic food chain are Altera and Xilinx. These two titans battle head-to-head and every few years exchange the lead. Currently, Altera has leapt or will leap ahead of Xilinx in technology, market share and market capitalization. But when it comes to innovation and new ideas, both companies typically offer incremental innovations rather than risky quantum leaps ahead. They are both clearly pursuing a policy that chases the high end, fat margin devices, focusing more and more on the big, sophisticated end-user who is most happy with greater complexity, capacity and speed. Those margin leaders are Xilinx’s Virtex families and Altera’s Stratix series. The sweet spot for these devices are low volume, high cost equipment like network equipment, storage systemcontroller and cell phone base stations. Oddly though, Altera’s recent leap to the lead can be traced to their mid-price Arria and low-price Cyclone families that offered lower power and lower price point with the right level of functionality for a wider swath of customers. Xilinx had no response having not produced a similarly featured device from the release of the Spartan3 (and its variants) until the arrival of the Spartan6 some 4 years later. This gap provided just the opportunity that Altera needed to gobble up a huge portion of a growing market. And then, when Xilinx’s Spartan6 finally arrived, its entry to production was marked by bumpiness and a certain amount of “So what?” from end-users who were about to or already did already migrate to Altera.
The battle between Altera and Xilinx is based on ever-shrinking technology nodes, ever-increasing logic capacity, faster speeds and a widening variety of IP cores (hard and soft) and, of course, competitive pricing. There has been little effort on the part of either company to provide any sort of quantum leap of innovation since there is substantial risk involved. The overall programmable logic market is behaving more like a commodity market. The true differentiation is price since the feature sets are basically identical. If you try to do some risky innovation, you will likely have to divert efforts from your base technology. And it is that base technology that delivers those fat margins. If that risky innovation falls flat, you miss a generation and lose those fat margins and market share.
Xilinx’s recent announcement of the unfortunately named Zynq device might be such a quantum innovative leap but it’s hard to tell from the promotional material since it is long on fluff and short on facts. Is it really substantially different from the Virtex4FX from 2004? Maybe it isn’t because its announcement does not seem to have instilled any sort of fear over at Altera. Or maybe Altera is just too frightened to respond?
Lattice Semiconductor has worked hard to find little market niches to serve. They have done this by focusing mostly on price and acquisitions. Historically the leader in in-system programmable devices, Lattice saw this lead erode as Xilinx and Altera entered that market using an open standard (rather than a proprietary one, as Lattice did). In response, Lattice moved to the open standard, acquired FPGA technology and tried to develop other programmable niche markets (e.g., switches, analog). Lattice has continued to move opportunistically; shifting quickly at the margins of the market to find unserved or underserved programmable logic end-users, with a strong emphasis on price competitiveness. They have had erratic results and limited success with this strategy and have seen their market share continue to erode.
Microsemi owns the antifuse programmable technology market. This technology is strongly favored by end-users who want high reliability in their programmable logic. Unlike the static RAM-based programmable technologies used by most every other manufacturer, antifuse is not susceptible to single event upsets making it ideal for space, defense and similar applications. The downside of this technology is that unlike static RAM, antifuse is not reprogrammable. You can only program it once and if you need to fix your downloaded design, you need to get a new part, program it with the new pattern and replace the old part with the new part. Microsemi has attempted to broaden their product offering into more traditional markets by offering more conventional FPGAs. However, rather than basing their FPGA’s programmability on static RAM, the Microsemi product, ProASIC, uses flash technology. A nice incremental innovation offering its own benefits (non-volatile pattern storage) and costs (flash does not scale well with shrinking technology nodes). In addition, Microtec is already shipping a Zynq-like device known as the SmartFusion family. The SmartFusion device has hard analog IP included. As best I can tell, Zync does not include that analog functionality. SmartFusion is relatively new, I do not know how popular it is and what additional functionality its end-users are requesting. I believe the acceptance of the SmartFusion device will serve as a early bellwether indicator for the acceptance of Zynq.
Quicklogic started out as a more general purpose programmable logic supplier based on a programming technology similar to antifuse with a low power profile. Over the years, Quicklogic has chosen to focus their offering as more of a programmable application specific standard product (ASSP). The devices they offer include specific hard IP tailored to the mobile market along with a programmable fabric. As a company, their laser focus on mobile applications leaves them as very much a niche player.
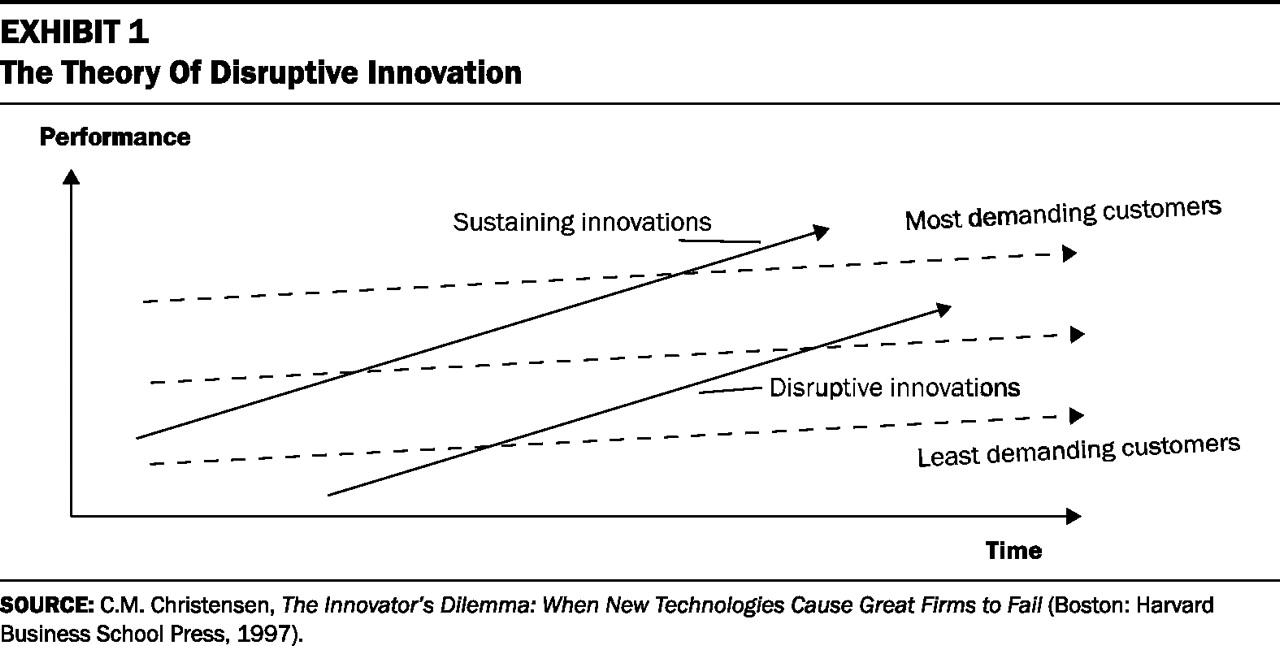
In recent years, a number of startups have entered the marketplace. While one might have thought that they would target the low end and seek to provide “good enough” functionality at a low price in an effort to truly disrupt the market from the bottom, gain a solid foothold and sell products to those overserved by what Altera and Xilinx offer; that turns out not to be the case. In fact, two of the new entrants (Tabula and Achronix) are specifically after the high end, high margin sector that Altera and Xilinx so jealously guard.
The company with the most buzz is Tabula. They are headed by former Xilinx executive, Dennis Segers, who is widely credited with making the decisions that resulted in Xilinx’s stellar growth in the late 1990s with the release of the original Virtex device. People are hoping for the same magic at Tabula. Tabula’s product offers what they refer to as a SpaceTime Architecture and 3D Programmable Logic. Basically what that means is that your design is sectioned and swapped in and out of the device much like a program is swapped in and out of a computer’s RAM space. This provides a higher effective design density on a device having less “hard logic”. An interesting idea. It seems like it would likely utilize less power than the full design realized on a single chip. The cost is complexity of the design software and the critical nature of the system setup (i.e., the memory interface and implementation) on the board to ensure the swapping functionality as promised. Is it easy to use? Is it worth the hassle? It’s hard to tell right now. There are some early adopters kicking the tires. If Tabula is successful will they be able to expand their market beyond where they are now? It looks like their technology might scale up very easily to provide higher and higher effective densities. But does their technology scale down to low cost markets easily? It doesn’t look like it. There is a lot of overhead associated with all that image swapping and its value for the low end is questionable. But, I’ll be the first to say: I don’t know.
Achronix as best I can tell has staked out the high speed-high density market. That is quite similar to what Tabula is addressing. The key distinction between the two companies (besides Achronix’s lack of Star Trek-like marketing terminology) is that Achronix is using Intel as their foundry. This might finally put an end to those persistent annual rumors that Intel is poised to purchase Altera or Xilinx (is it the same analyst every time who leaks this?). That Intel relationship and a less complex (than Tabula) fabric technology means that Achronix might be best situated to offer their product for those defense applications that require a secure, on-shore foundry. If that is the case, then Achronix is aiming at a select and very profitable sector that neither Altera nor Xilinx will let go without a big fight. Even if successful, where does Achronix expand? Does their technology scale down to low cost markets easily? I don’t think so…but I don’t know. Does it scale up to higher densities easily? Maybe.
SiliconBlue is taking a different approach. They are aiming at the low power, low cost segment. That seems like more of a disruptive play. Should they be able to squeeze in, they might be able to innovate their way up the market and cause some trouble for Xilinx and Altera. The rumored issue with SiliconBlue is that their devices aren’t quite low power enough or quite cheap enough to fit their intended target market. The other rumor is that they are constantly looking for a buyer. That doesn’t instill a high level of confidence now, does it?
So what does all this mean? The Microsemi SmartFusion device might be that quantum innovative leap that most likely extends the programmable logic market space. It may be the one product that has the potential to serve an unserved market and bring more end-user and applications on board. But the power and price point might not be right.
The ability of any programmable logic solution to expand beyond the typical sweet spots is based on its ability to displace other technologies at a lower cost and with sufficient useful functionality. PLDs are competing not just against ASSPs but also against multi-core processors and GPUs. Multi-core processors and GPUs offer a simpler programming model (using common programming languages), relatively low power and a wealth of application development tools with a large pool of able, skilled developers. PLDs still require understanding hardware description languages (like VHDL or Verilog HDL) as well as common programming languages (like C) in addition to specific conceptual knowledge of hardware and software. On top of all that programmable logic often delivers higher power consumption at a higher price point than competing solutions.
In the end, the real trick is not just providing a hardware solution that delivers the correct power and price point but a truly integrated tool set that leverages the expansive resource pool of C programmers rather than the much smaller resource puddle of HDL programmers. And no one, big or small, new or old, is investing in that development effort.

 There is a huge focus on big data nowadays. Driven by ever decreasing prices and ever increasing capacity of data storage solutions, big data provides magical insights and new windows into the exploitation of the long tail and addressing micro markets and their needs. Big data can be used to build, test and validate models and ideas Big data holds promise akin to a panacea. It is being pushed as a universal solution to all ills. But if you look carefully and analyze correctly what big data ultimately provides is what Marshall MacLuhan described as an accurate prediction of the present. Big data helps us understand how we got to where we are today. It tells us what people want or need or do within a framework as it exists today. It is bounded by today’s (and the past’s) possibilities and ideas.
There is a huge focus on big data nowadays. Driven by ever decreasing prices and ever increasing capacity of data storage solutions, big data provides magical insights and new windows into the exploitation of the long tail and addressing micro markets and their needs. Big data can be used to build, test and validate models and ideas Big data holds promise akin to a panacea. It is being pushed as a universal solution to all ills. But if you look carefully and analyze correctly what big data ultimately provides is what Marshall MacLuhan described as an accurate prediction of the present. Big data helps us understand how we got to where we are today. It tells us what people want or need or do within a framework as it exists today. It is bounded by today’s (and the past’s) possibilities and ideas.

{kind=link}