

This post’s headline is the actual version of the often-misquoted line from the classic film The Treasure of the Sierra Madre. In the film, it is spoken by the character “Gold Hat“, the lead of a gang of bandits, who, masquerading as federales, are threatening to rob and possibly kill the group of gold miners led by the protagonist Fred C. Dobbs.
Maybe you don’t have to show any stinking badges but there is no doubt that there are some situations where flashing a badge does grant you instant respect.
And now you can! Badges! is a brand-new mobile app just released by Formidable Engineering Consultants that provides the instant veneer of authority and the illusion of honor and respect you so richly deserve.
Now Available in the Google Play store!
You need this cutting-edge app, and you need it now and you can get it here and you should.
How Do I Use It?
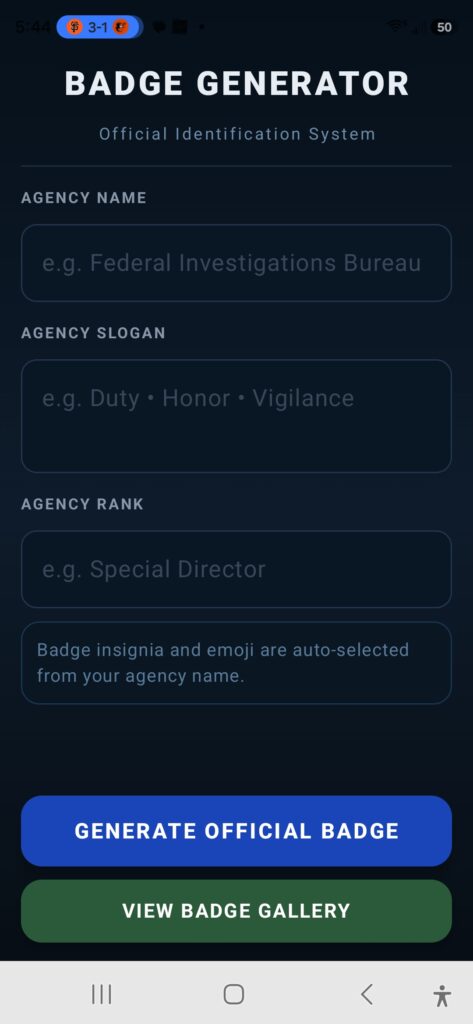
Once you start the app, it will automatically provide you with a screen allowing you to enter your agency information to allow construction of a suitable badge.
The first entry is the agency name. Perhaps “Nordic Division” tickles your fancy. The next step would be to develop an appropriate and suitable agency slogan. The Nordic Division’s slogan is well known to be “To Freeze and Protect”. You simply enter it in the appropriate slot. Finally, you select the appropriate rank of you – the officer of the agency in question. Obviously, for this agency that would be “Freelance Viking”.
With the badge information complete, push the “GENERATE OFFICIAL BADGE” button and observe:

The fully generated badge ready to be shared along with the official badge number for identification purposes.
The badge can be saved to the “badge gallery” for later usage by pushing the SAVE button.
You can prepare the public for your arrival by pushing the SIREN button. Once you have arrived, you can enter to the appropriate accompaniment by pushing the FANFARE button.
And, finally, a full-sized display of the badge is enabled using the FULLSCREEN button
The full screen badge image is every bit as authoritative and impressive as you might imagine:

FAQ
- This app is a transformational! How much does it cost?
Badges! is an absolutely free download from the Google Play store. - Free? That’s crazy! How do you do that?
How do we do it? Volume. - What sort of personal information does Badges! collect?
Badges! collects no personal information. It does not review or collect your experiences or store them anywhere. They are stored on your phone and visible only to you. It should be noted though that by downloading the application you have likely identified yourself as someone keen on badges. - How many badges can I keep in my gallery?
A lot! When you find out do let us know! - When will the iOS version be available?
Our team of expert programmers are hard at work developing a native iOS version of this application so that iPhone users can also reek of authority. The iOS platform does have some limitations that make badge development more encumbered, but the next iOS version may allow badge production more deliberately. - I have another question, but I don’t know what it is.
Feel free to post your questions to android at formidableengineeringconsultants dot com. If it’s a really good question, we’ll even answer it.







